2018 Winner
Machine learning for smarter seed selectionThe Inspire Challenge is an initiative to challenge partners, universities, and others to use CGIAR data to create innovative pilot projects that will scale. We look for novel approaches that democratize data-driven insights to inform local, national, regional, and global policies and applications in agriculture and food security in real time; helping people–especially smallholder farmers and producers–to lead happier and healthier lives.
This proposal was selected as a 2018 winner, with the team receiving 100,000 USD to put their ideas into practice.
Machine learning for smarter seed selection
Each year, farmers around the world decide what to plant in their fields. The seeds they choose matter greatly; livelihoods and food security, for the farmer and others linked by the global food system, are at stake. While some seed varieties have the potential to produce record-breaking yields, they also carry risk and depend on specific conditions. Other seed varieties have more stable, but comparatively lower yields.
Using machine learning, researchers can predict both yields and risks associated with different seeds at a specific farm and select a mixture of varieties that represents the optimal trade-off. Using data from hundreds of on-farm and experimental International Maize and Wheat Improvement Center (CIMMYT) sites, as well as a network of seed companies producing varieties for diverse agro-ecologies, BioSense will develop machine learning models that predict the performance of seed varieties in particular conditions in order to advise maize farmers in Mexico on what to plant.
The project benefits seed companies and farmers alike. Seed companies can ensure that they sell the best seed variety possible for a specific region, which reduces the risk of marketing the wrong type of seed to the target population. In turn, this reduces farmers’ risk of low crop yield or crop failure. It also minimizes risk for government programs that subsidize maize seed to support smallholder farmers. As smallholder farmers’ production increases, so will Mexico’s maize self-sufficiency.
Finally, the project will serve as a decision support tool. Through climate prediction data, seed companies and farmers can plan for the use of seeds best suited to changing, future climates. This service will be provided for free to the seed companies involved with the project–most of which are small and otherwise lack the capital needed to access decision support services.
Team
Dr Sanja Brdar | Email
Head of Knowledge Technologies Group at BioSense Institute
Marko Panić | Email
Machine Learning Expert at BioSense Institute
Oskar Marko | Email
Data Analytics Expert at BioSense Institute
Gordan Mimifá
Weather and Climate Expert at BioSense Institute
Dr Kai Sonder | Email
Head of GIS Unit at CIMMYT
Dr Alberto Chassaign
Maize Seed systems specialist for Latin America at CIMMYT
Project Partners
CIMMYT provides maize growth and yield data from hundreds of on-farm and experimental sites.
BioSense is developing machine learning models that predict the performance of maize seed varieties in particular conditions through the use of deep learning, big data analytics, and satellite data processing.
Step by step
US$100K grant
The project was one of five winners of the Inspire Challenge 2018 and was awarded US$100K at the second annual convention of the CGIAR Platform for Big Data in Agriculture, 3-5 October 2018.

Database formed
The team created a database with all the necessary data about maize production in Mexico. It includes satellite images, performance data, and weather information.
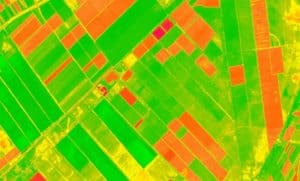
Example of satellite image data with normalized difference vegetation index calculated.
Digitisation of field records
Hundreds of samples about maize growth and agricultural practice on CIMMYT’s test fields were integrated into the database.
Samples of new maize varieties were collected from 126 evaluation sites in 2017 and from 115 in 2018.
Project partner Biosense used machine learning techniques to determine which of the maize varieties would work best at any of these sites, comparing climate, soils, and other parameters. If the developed algorithm is successful, the team hopes to use it in other countries in order to give a variety of recommendations to farmers in specific locations.
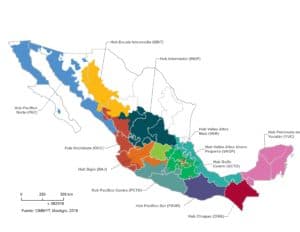
CIMMYT’s maize testing sites from which data was collected for the team’s Mexico maize production database.
Dataset enrichment
The team developed modules for automatic acquisition of soil data, historical weather data, and satellite vegetation indices based on the GPS location.
Feature engineering
The team then engineered meteorological and satellite features that are good indicators of yield, based on the domain knowledge.
Data fusion
The team fused data coming from heterogeneous sources into a single database suitable for machine learning.
Machine learning
A data-driven yield prediction model will be developed based on soil and climate data, as well as a model for assessing yield stability—the hybrids’ response to drought and other factors.
Development of seed selection algorithm
A module for finding the portfolio of hybrids with optimal yield/risk trade-off at the particular farm will be developed. Fertiliser application will be optimised using machine learning and evolutionary algorithms.
Evaluation
The system will be thoroughly tested and its performance will be evaluated. The team will then assess its potential for scaling up on a global level.
Stay tuned for more updates!
Project News and Resources

Machine learning for smarter seed selection to reduce risks for Mexican maize farmers

Drones fly in to change the way we work in research fields

Now, get critical seed data in one click
Multinational training workshop on analytical tools builds momentum on crop improvement

Digital agriculture holds great promise for agricultural development
Meet all the Winners














