Mapping Cropland in South Asia using Landsat data on Google Earth Engine

Figure 8. Methodology for mapping 30-m cropland extent. Pixel-based Random Forest (RF) machine learning algorithm for mapping cropland extent using Landsat 30-m data.
Abstract
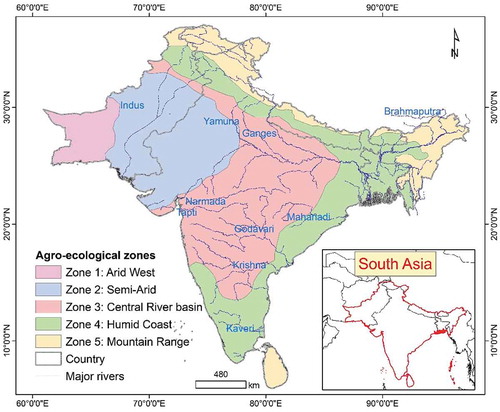
South Asia has a staggering 900 million people (~43% of the population) who face food insecurity or severe food insecurity as per United Nations, Food and Agriculture Organization’s (FAO) the Food Insecurity Experience Scale (FIES). The existing coarse-resolution (≥250-m) cropland maps lack precision in geo-location of individual farms and have low map accuracies. This also results in uncertainties in cropland areas calculated from such products. Thereby, the overarching goal of this study was to develop a high spatial resolution (30-m or better) baseline cropland extent product of South Asia for the year 2015 using Landsat satellite time-series big-data and machine learning algorithms (MLAs) on the Google Earth Engine (GEE) cloud computing platform. To eliminate the impact of clouds, 10 time-composited Landsat bands (blue, green, red, NIR, SWIR1, SWIR2, Thermal, EVI, NDVI, NDWI) were derived for each of the three time-periods over 12 months (monsoon: Days of the Year (DOY) 151–300; winter: DOY 301–365 plus 1–60; and summer: DOY 61–150), taking the every 8-day data from Landsat-8 and 7 for the years 2013–2015, for a total of 30-bands plus global digital elevation model (GDEM) derived slope band. This 31-band mega-file big data-cube was composed for each of the five agro-ecological zones (AEZ’s) of South Asia and formed a baseline data for image classification and analysis. Knowledge-base for the Random Forest (RF) MLAs were developed using spatially well spread-out reference training data (N = 2179) in five AEZs. The classification was performed on GEE for each of the five AEZs using well-established knowledge-base and RF MLAs on the cloud. Map accuracies were measured using independent validation data (N = 1185). The survey showed that the South Asia cropland product had a producer’s accuracy of 89.9% (errors of omissions of 10.1%), user’s accuracy of 95.3% (errors of commission of 4.7%) and an overall accuracy of 88.7%. The National and sub-national (districts) areas computed from this cropland extent product explained 80-96% variability when compared with the National statistics of the South Asian Countries. The full-resolution imagery can be viewed at full-resolution, by zooming-in to any location in South Asia or the world, and the cropland products of South Asia downloaded from The Land Processes Distributed Active Archive Center (LP DAAC) of National Aeronautics and Space Administration (NASA) and the United States Geological Survey (USGS).
Gumma, Murali Krishna, Prasad S. Thenkabail, Pardhasaradhi G. Teluguntla, Adam Oliphant, Jun Xiong, Chandra Giri, Vineetha Pyla, Sreenath Dixit, and Anthony M. Whitbread. “Agricultural cropland extent and areas of South Asia derived using Landsat satellite 30-m time-series big-data using random forest machine learning algorithms on the Google Earth Engine cloud.” GIScience & Remote Sensing (2019): 1-21.
December 11, 2019
CGIAR-CSI

