Webinar summary – Can machine learning technologies be useful to create or complete ontologies in agriculture?
The Ontologies Community of Practice launched a webinar series to debate, share, and advance our thinking on selected topics in the domain of ontologies. During this second webinar we learned about machine learning technologies and the link with ontologies.

***
What is machine learning?
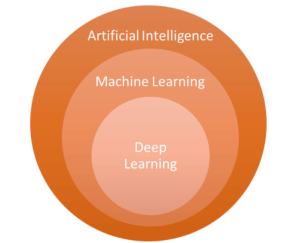
In order to introduce machine learning we must first talk about artificial intelligence (AI). AI was founded as an academic discipline in 1956, it essentially studies how human-like intelligence can be incorporated into machines.
Machine learning is the application of artificial intelligence to computers, it is different from traditional programming because in programming it is the task of the programmer to anticipate and handle all the situations, while in machine learning the computer teaches itself how to solve the problem. Although machine learning is built upon a statistical framework, it differs from statistics; the latter is mostly concerned about finding relationships between variables and what they mean. Statistics stresses interpretability, whereas machine learning is concerned about the results of applying the model to data. It emphasizes prediction, sacrificing interpretability for accuracy.
Machine learning tasks can be divided into three main categories: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, models are trained using labelled data. These contain data samples which have each an assigned label. The term supervised comes from the fact that the association between the data sample and the label is usually performed by a human supervisor. Some applications of supervised learning are image classification, pattern recognition, market forecasting, and process parameter optimization.
Unsupervised learning does not use labelled data, as in supervised learning, but the model infers by mining for rules and detecting patterns in the data. Unsupervised learning applications include matching advertising to specific population groups and high-resolution image compression.
Al reinforcement learning methods share the same goal: to solve sequential decision tasks using trial and error interactions with the environment. An agent must actively explore its environment to observe the effects of its actions, which usually cannot be undone. Popular uses of reinforcement learning are speech recognition, games, driving, and robotics.
Deep learning is a sub-field of machine learning, in which the step of extracting the significative features is performed by the model itself. This means it can handle a very large set of features, effectively capturing the complexity of environments in which everything affects everything else. Its applications include image recognition, language translation, and email security. Deep learning is what powers the most human-like artificial intelligence. It is considered to be the next evolution of machine learning.
Another popular term is data mining. It describes the activity of analyzing the very large datasets used in machine learning, which are referred to as big data.
Can machine learning technologies be useful to create or complete ontologies in agriculture?
Below are the main points discussed during the webinar:
- Ontologies are the backbone of the semantic web. They allow inferring rather than only selecting. Ontology matching, the process of finding the semantic mappings between two given ontologies, can be performed using machine learning and greatly contribute to the effectiveness of the semantic web.
- Ontologies are also used as a pre-processing step in machine learning activities. They are very useful in differentiating ambiguous terms and ensuring theta quality.
- Machine learning can help in processing large amounts of text and extracting summaries and sets of subject-predicate-object relationships which can populate ontologies.
- Human supervision is still needed to double-check the results of machine learning when building ontologies.
We thank the panelists for their engaging and inspirational insights:
Milko Škofič
Expert in information systems design, data analysis and capacity building
Milko Škofič is a systems analyst with over 20 years of experience in design, development and implementation of plant genetic resources and forestry information systems. He has extensive experience in collecting, aggregating and analyzing data from heterogeneous and geographically dispersed scientific networks. Currently he supports the creation of national information platforms for nutrition in ten countries.
Xingyi Song
Research associate at the University of Sheffield
Xingyi Song is a research associate at the Natural Language Processing (NLP) group (GATE Team) managed by Prof. Kalina Bontcheva, working in the biomedical domain name/entity and sentiment recognition and analysis. He holds a PhD from the University of Sheffield in Training Machine translation for human acceptability. Song’s work mainly focuses on machine translation, natural language processing and machine learning.
Diana Maynard
Senior research fellow at the University of Sheffield
Dr. Diana Maynard is a senior research fellow at the University of Sheffield, UK, where she has been researching and developing tools for text mining and social-media analysis since 2000. She is one of the key developers of the widely used open source Natural Language Processing (NLP) toolkit GATE, and has special interests in multilinguality, social media, and sentiment analysis.
The next webinar in this year’s Ontologies CoP webinar series will take place in September (exact date TBD) on the topic of ‘Image annotation and Ontologies.’ Please join to the Ontologies LinkedIn group and subscribe to the mailing list if you wish to receive more information and reminders on this topic.
June 25, 2019
Milko Škofič
Expert in information systems design, data analysis and capacity building
Latest news


Hi Reean – we have a journal paper coming out soon which explains the methodology. You can also find the relevant project deliverables here https://gate.ac.uk/projects/knowmak
Hope that helps
Diana
This is a good explanation, but actually i didn’t understand how the term recognition tool and word embedding process is used to extract the keywords from the entity.
For a project, I have build an ontology and want to generate keyword related to the classes/items to populate the ontology. Any advice how to do so.
Thanks